

Dnes vám řeknu příběh o jedné křivce, která vám pomůže lépe chápat tento svět a dělat lepší rozhodnutí. Ale nebojte se. V článku nejsou žádné vzorečky. Jen příběhy.
Křivka, o které se budeme bavit, se jmenuje Gaussova neboli křivka normálního rozdělení.
Je to naprosto fascinující věc. Měla by se učit na základních školách. Ale neučí. Nebo si to alespoň nepamatuju. Nebo jsem ji tehdá nepochopil.
Co vlastně říká Gaussova křivka, jsem pochopil až dlouho po základce. Ten okamžik si pamatuju naprosto přesně. Bylo to na vysoké škole při ústní zkoušce ze statistiky.
Možná si říkáte, že je to trošku pozdě. Ale paní profesorka měla tehdy se mnou soucit.
Když viděla, že v tom tápu, tak mi všechno dovysvětlila. A když zjistila, že jsem to pochopil a že se celkem rychle chytnu, tak jsem dokonce i tu zkoušku ze statistiky s odřenýma ušima dal.
Dále jsem na škole vystudoval takové předměty jako ekonometrie a operační analýzy, což jsou obory pracující s daty a statistikou. Statistiku teď používám v práci, v rámci Lean Six Sigma. Ale nejsem statistik. Proto se trochu zdráhám teď psát tyto řádky. Pokud jsou mezi vámi statistici a zjistíte, že říkám něco špatně nebo nepřesně, nebojte se mě vzít za slovo a napište mi. Teď už ale pojďme na první příběh.
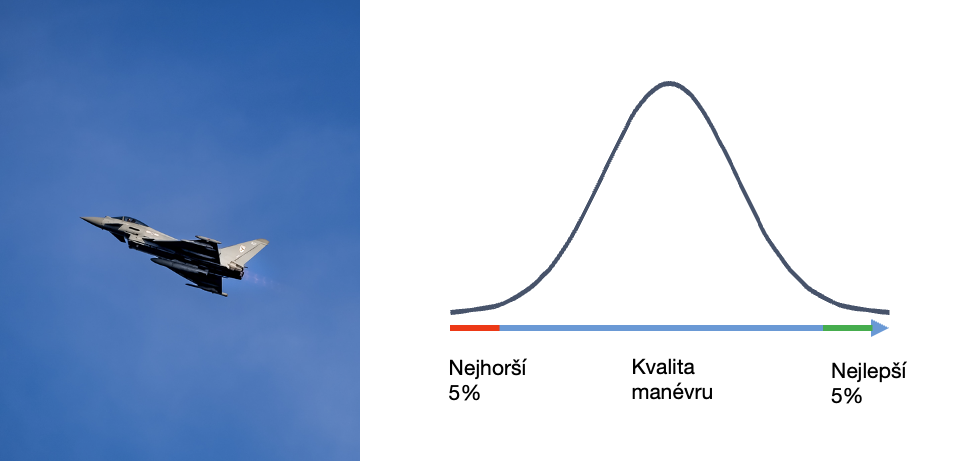
Příběh o stíhacích pilotech a jejich manévrech
Tento příběh vypráví izraelský psycholog Daniel Kahneman ve své knize Myšlení rychlé a pomalé:
„K nejzajímavějšímu okamžiku mé kariéry patří zážitek výuky leteckých instruktorů v izraelském vojenském letectvu o psychologii efektivního tréninku. Přednášel jsem jim právě o důležitém principu trénování dovedností, a sice že odměna za zlepšený výkon funguje lépe než trest za chybný výkon.“
Toto tvrzení potvrzuje řada vědeckých důkazů z výzkumu chování holubů, krys i jiných zvířat a také lidí.
„Když jsem dokončil svou entuziastickou řeč,“ pokračuje Kahneman, „jeden z nejzkušenějších instruktorů ve skupině zvedl ruku a přednesl svůj názor:
‚Při mnoha příležitostech jsem pochválil letecké kadety za čisté provedení nějakého akrobatického manévru. Při dalším pokusu stejný manévr téměř vždy pokazili. A naopak. Často jsem kadeta seřval do sluchátek za špatné provedení. A obecně platí, že si při dalším pokusu vedl lépe. Takže nám tady, prosím, nevykládejte, že odměna funguje, a trest nefunguje, protože je to přesně naopak.‘“
Kahneman vzal křídu a nakreslil na zem terč.
Pak požádal všechny důstojníky v místnosti, aby se postavili stejně daleko od terče, otočili se zády, a hodili na terč minci.
Kahneman poté každému změřil vzdálenost od středu terče a napsal hodnoty na tabuli se jmény důstojníků, seřazené od nejlepšího po nejhoršího.
Pak je nechal házet ještě jednou. Výsledky druhého pokusu připsal na tabuli:
„Podívejte se, co se stalo: Ti, co hodili minci v prvním pokusu nejblíže středu, mají v druhém hodu mnohem horší výsledek. A naopak, ti co hodili dále, se v druhém pokusu zlepšili.“
A Kahneman říká: „Vyložil jsem instruktorům, že to, co vidí na tabuli, je totéž, jako to, co jsme slyšeli o výkonu kadetů v akrobatických manévrech: Po špatném výkonu typicky následovalo zlepšení a po výborném výkonu zhoršení, aniž by se na tom podílela chvála, či potrestání.“
Tyto výsledky jsou jen hra statistiky.
Příběh o studentech tipujících odpovědi v testu
Další podobný příklad uvádí Derek Muller, autor skvělého videokanálu Veritassium, ve svém videu na stejné téma jako tento článek:
Představte si, že 100 studentů píše test se zaškrtávacími odpověďmi:
Test má 100 otázek. Každá má hodnotu jednoho bodu. Každá otázka má dvě možné odpovědi: Pravda a nepravda:

V tomto hypotetickém testu ale všichni studenti své odpovědi pouze tipují a náhodně zaškrtávají odpovědi.
Jaké budou asi výsledky?
Zřejmě očekáváte že hodně studentů bude mít kolem 50 bodů, že většina bude mít tak 40–60 bodů.
Ale pravděpodobně mezi studenty budou i tací, kteří budou mít výrazně lepší výsledky
Bude mezi nimi někdo, kdo natipuje správně všech 100 otázek?
Pravděpodobnost je malá, ale možné to je.
Pokud byste třeba patřili mezi těch pár šťastlivců, co natipovali 80 bodů nebo více, je pravděpodobné, že při dalším testu budete mít štěstí menší.
I zde se jedná o hru statistiky. Říká se jí regrese k průměru.
Výška vašich rodičů a regrese k průměru
Koncem 19. století tento jev pojmenoval sir Francis Gelton, slavný vědec zabývající se mnoho obory (a také byl vzdálený bratranec Charlese Darwina).
Výsledky svého bádání shrnul v roce 1886 do článku s názvem Regrese k průměrnosti dědičného vzrůstu.
Gelton totiž měřil, jak vysoké jsou děti oproti svým rodičům. A z experimentu mu vyšlo, že lidé, kteří mají extrémně vysoké rodiče, tak bývají menší než oni. Naopak velmi malí rodiče měli v průměru vyšší děti než oni sami.
Regrese k průměru tedy říká, že extrémní jevy jsou málo pravděpodobné na rozdíl od těch průměrných, a tudíž další opakování stejného náhodného jevu bude velmi pravděpodobně méně extrémní. Bude blíž k průměru.
Takže je jasné, že když se kadetovi povede extrémně dobrý manévr, další pokus bude nejspíš průměrnější, čili horší.
Pokud provede extrémně špatný manévr, ten další bude také průměrnější, tentokrát lepší.
Stejně to funguje v příběhu o tipování testu u zkoušky nebo u výšky rodičů a jejich dětí.
Neznalost regrese k průměru může vést k hodně špatným rozhodnutím.
Třeba důstojníci v izraelské armádě si regresi chybně vyložili tak, že když kadetům vynadají, tak to má dobrý efekt na jejich výkon.
Netušili ale, že to, co pozorují je hra statistiky. Jejich nadávky pravděpodobně výkon vůbec neovlivnily.
„Stav deprimovaných dětí, kterým byl podáván energetický nápoj, se za tři měsíce výrazně zlepšil.“
Tento novinový titulek uvádí Kahneman jako příklad potenciálně zavádějící informace.
Deprimované děti jsou jistě extrémní případ.
A protože je psychický stav proměnlivý, je pravděpodobné, že se ten stav za ty tři měsíce zlepšil bez ohledu na to, jaké nápoje děti pily.
Kam dát ve městě kamery měřící rychlost?
Derek Muller uvádí ještě příklad s kamerou, která hlídá překročení rychlosti vozidel.
Jak se rozhodnout, kam dát ve městě kamery, které měří rychlost?
Logicky z tisíce možných křižovatek nebo úseků vyberete ty, kde byla loni nejvyšší nehodovost.
A na ta místa dáte kamery.
Voilà, co se stane? Další rok nehodovost klesne.
Ale pozor, to vůbec nemusí být efekt těch kamer.
To může být jen proto, že v minulém roce se tam stal extrémní jev. A letos je nehodovost prostě blíž normálu.
Hora říp, nebo zvon?
Kdybyste si vzali jednu z věcí z našich příběhů
- Kvalitu leteckých manévrů
- Výsledky testů náhodně tipujících studentů
- Výšku lidí v studii sira Geltona
Vzali byste dostatečný počet vzorků a zobrazil je v grafu zjistili byste, že graf má tvar kopce:
Tedy tvar připomínající právě Gaussovu křivku.
Možná někdo říká, že to připomíná horu Říp. Anglicky mluvicím pak připomíná zvon. Bell curve.
Všechny tři věci, co jsem jmenoval, jsou náhodné veličiny.
A platí taková zajímavá věc: Když je náhodná veličina složená z mnoha jiných drobných náhodných veličin, pak jejich výstup má právě tady ten tvar toho kopce.
Výstupem této náhodné veličiny je právě Gaussova křivka neboli tato náhodná veličina má velmi často normální rozdělení.
To vychází z centrální limitní věty.
Takže kdybyste vzali výšku náhodného vzorku lidí, udělali byste histogram, a pak obtáhli tužkou, vyšla by vám práv křivka normálního rozdělení.
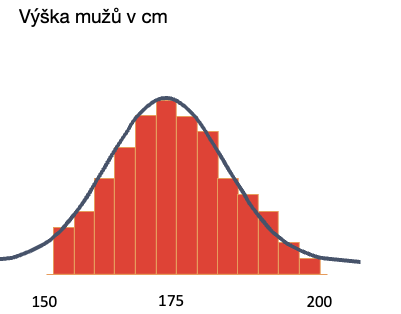
Je to proto, že právě i růst je způsoben mnoha malými náhodnými prvky, našimi geny, stravou a dalšími vlivy.
Stejně tak jako ty letecké, akrobatické prvky jsou způsobeny drobnými nuancemi, tisíci drobnými nuancemi, které se vzájemně nasčítají.
U toho tipovacího testu je to velmi zřejmé. Výsledek toho testu je totiž součet sta jiných náhodných veličin. Proto se dá očekávat, že i výstupy budou mít právě tady tu Gaussovu křivku.
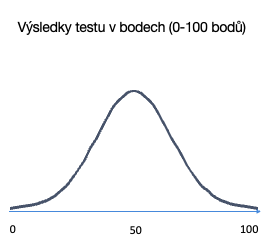
Z křivky je vidět, že většina výsledků bude kolem středu. Budou existovat i extrémnější výsledky směrem k oběma stranám, ale těch už bude jen velmi málo.
Třeba právě u té výšky, dejme tomu mužů (muži a ženy mají statisticky jinou křivku výšky), umí statistika následující věc:
Když si vyberete dostatečně velký vzorek a změříte si četnosti, tak dokážete odhadnout křivku normálního pro celou populaci.
A na základě té křivky se pak třeba můžete podívat na její vrchol.
A tam víte, že ta výška toho člověka, která je na tom vrcholu, tak to je vlastně medián populace.
Ta křivka dělí populaci na dvě poloviny. Polovina je vyšší a polovina je nižší.
Na serveru Our World In Data jsem k výšce našel nějaké informace:
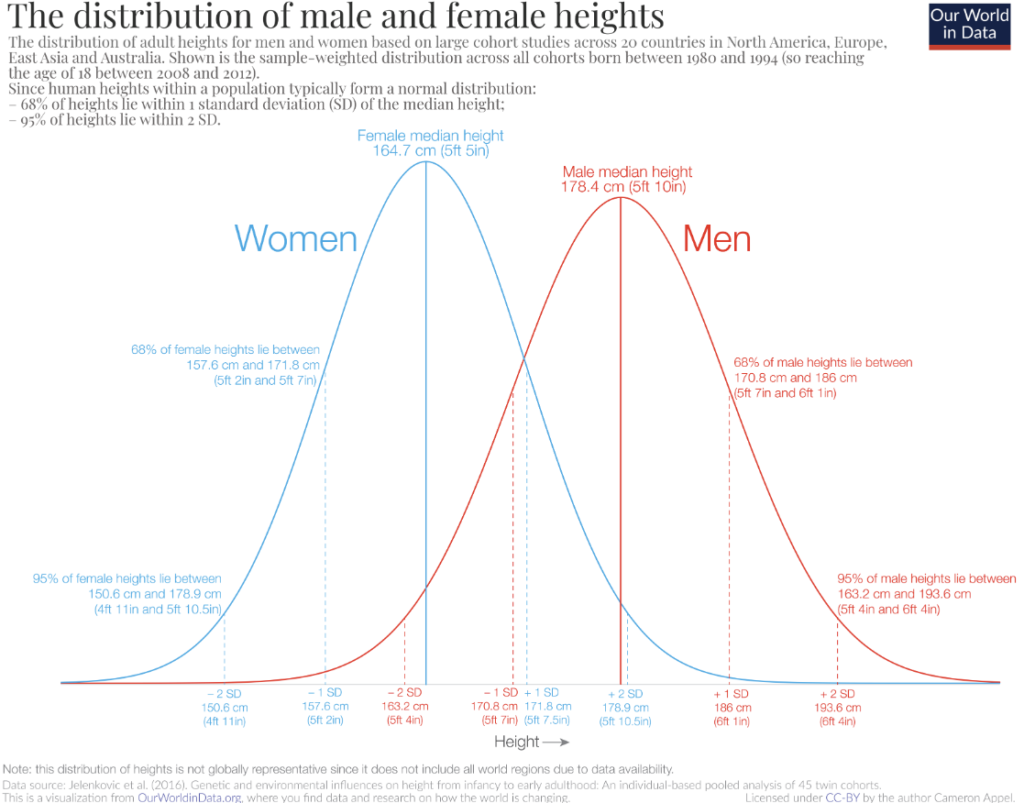
Konkrétně jsou to distribuce výšky dospělých mužů a žen ve dvaceti zemích v Severní Americe, v Evropě, ve východní Asii a v Austrálii mezi roky 2008 a 2012.
A vychází z toho, že střední hodnota výšky žen je 164 centimetrů a výšky mužů pak 178 centimetrů.
Ze získaných křivek lze také vyvodit, že
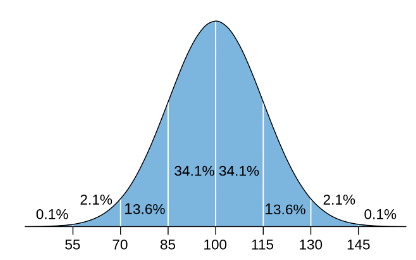
- 68 % žen má výšku 157 a 171 centimetry.
- 68 % mužů má výšku 170 a 186 centimetry.
(Proč zrovna 68 % ? To vychází z tzv. pravidla 68-95-99,7, což je velmi zajímavé chování Gaussovy křivky. O tom někdy příště)
Gaussova křivka umí také to, že když ji říznete v kterémkoliv bodě, tak dokážete spočítat v procentech, kolik lidí je třeba vyšších, nebo nižších než daná hodnota:
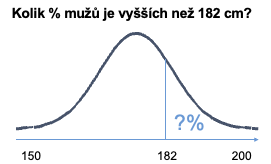
A to například v Excelu pomocí funkce NORM.DIST:

Tady ten princip se používá při kontrole kvality ve výrobě. Třeba u kovových součástek.
Vlastnosti vyrobených kusů nejsou vždy stejné, ale obvykle kopírují Gausovu křivku.
A ta váha nebo například tloušťka, hustota a různé jiné parametry se musí vejít do nějakých tolerancí, které ti zákazníci chtějí.
A právě pomocí vzorkování a normálního rozdělení se dá odhadnout a předpovídat, kolik procent výrobků bude právě mimo toleranci.
A dá se to pomocí toho i řídit.
Říká se tomu statistické řízení procesu.
Inteligence: 50 % populace má IQ vyšší než 100, 50 % nižší
Zajímavé je také měření inteligence. Inteligenční kvocient má dle definice tvar Gaussovy křivky.
Většina lidí má normální inteligenci a pár jedinců má extrémně vysokou, nebo naopak extrémně nízkou inteligenci.
A výpočet hodnoty IQ je přímo definován touto křivkou. Vysvětlím vám, jak se moderní IQ počítá:
Představte si, že uděláte IQ test na nějaké dostatečně velké, reprezentativní skupině lidí, třeba tisíce lidí.
A dáte jim nějaký test, kde můžou skórovat od nuly do tisíce bodů.
Výsledky pak seřadíte od nejlepšího do nejhoršího a rozdělíte je v půlce.
Pětistý člověk bude mít nějaké skóre, třeba 737 bodů z 1000, to je celkem jedno.
A tady tomu člověku přiřadíte hodnotu IQ 100.
Ze samotné definice IQ pak vyplývá, že polovina populace má IQ vyšší než 100 a polovina populace má IQ nižší než 100.
Možná vás toto překvapí, ale je to skutečně tak.
I psychopati jsou v populaci rozděleni dle Gausovy křivky
Stejně jako IQ mají normální rozdělení i jiné lidské vlastnosti, třeba agresivita nebo extroverze a introverze, sklony k autismu, schizofrenie nebo třeba psychopatie.
Psychiatrie měla historicky představu, že je to takový binární jev: Když je někdo schizofrenní, nebo není schizofrenní, je psychopat, nebo není psychopat.
Ve skutečnosti si to představte spíš jako křivku normálního rozdělení, kde věda udělala nějakou čáru, a řeklo se, že od těchto hodnot už jsou lidé psychopati.
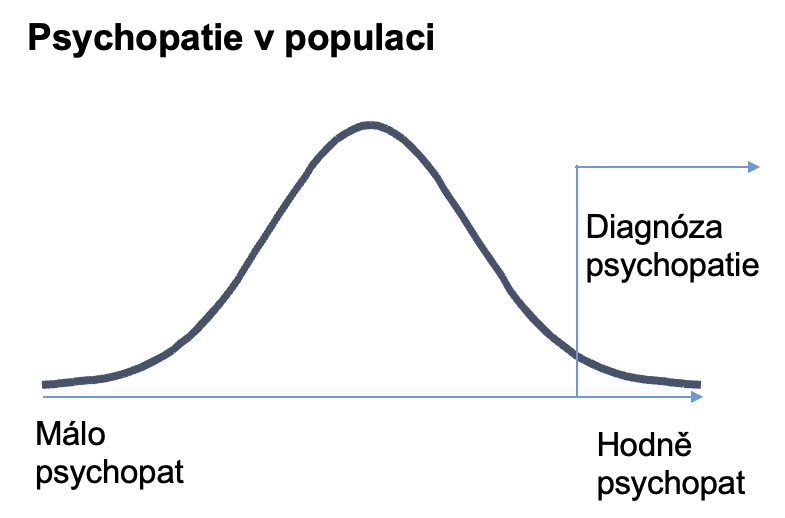
A může to být třeba právě proto, že tyto vlastnosti jsou určovány ne jedním genem, ale tisíci různými geny.
Právě zde vzniká ten efekt, kdy se sčítá mnoho náhodných prvků, proto mají tyto lidské vlastnosti často v populaci tvar křivky normálního rozdělení.
Svět je mnohem méně extrémnější, než v televizi
Pojďme se teď podívat na další případ, jak nám křivka normálního rozdělení pomáhá chápat dění ve společnosti.
V televizi nebo ve zprávách vidíme často různé extrémní chování:

- Lidé čekající ve frontě před Primarkem v první den otevření.
- Lidé, kteří se odpalují jako sebevražední atentátníci nebo střílejí po žácích a učitelích ve škole.
- Nebo naopak lidé, kteří bezelstně pomáhají likvidovat škody po tornádu.
- Nebo lidé s dokonalými těly v časopisech.
- Nebo třeba člověk, který zemře den poté, co mu byla aplikována vakcína.
Je dobré vědět, že tito lidé představují pravděpodobně ty extrémy na málo pravděpodobném chvostu v populaci.
Jestli před Primarkem čekaly stovky lidí, tak je to jenom drobounké procento z celé populace České republiky.
A ukazuje to ten velmi extrémní jev chování.
Stejně tak i sebevražední atentátníci, nebo naopak zase extrémně dobří lidé.
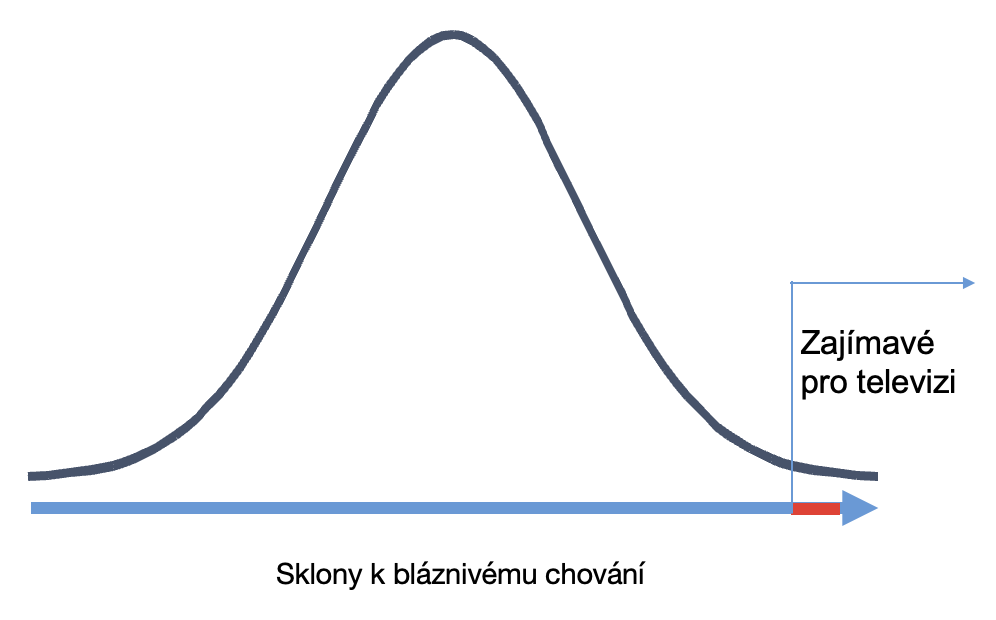
O středu křivky, o běžném, obvyklém chování lidí, se v televizi moc často nemluví.
Člověk tak může nabýt dojmu, že lidstvo zešílelo a že všichni jsou blázni.
Ale z pohledu normálního rozdělení, to, co televize ukazuje, jsou jenom ty extrémní chvosty na jednu, nebo druhou stranu.
Je to jen hra statistiky.
Rozdíly mezi muži nebo ženami? Existují. Ale o vás nebo o mě vám nic neřeknou.
Je tu ale ještě jedna věc, kterou je potřeba vědět o různých statistických rozděleních a pravděpodobnostech.
Hezky tento princip vysvětluje psycholožka Amy Cuddy. To je žena, která se proslavila svým TED talkem:
Mluví o tom, že gesta, která děláte, můžou ovlivňovat vaše chování.
Například, pokud jedete na pohovor a cestou ve výtahu zvednete ruce do „vítězného gesta“, jste sebevědomější a méně se bojíte.
Amy Cuddy byla v nějakém podcastu, myslím, že to bylo zde u Simona Sinka, a ten se jí ptal: „Dobře. Znamená to tedy, že když půjdu někam na pohovor a zvednu při tom na minutu ruce nahoru, tak budu úspěšnější?“
Amy Cuddy na to říká: „Já nevím. Já nedokážu říct vůbec nic o vás. Já pracuji se statistikou. Psychologie nedokáže říct, co bude fungovat vám. Na velkých číslech ukazuje průměrné rozdíly mezi skupinami lidí.“
Určitě totiž znáte různé poučky a historky, v čem se liší muži a ženy.
Některé jsou i podloženy daty nebo podobnými výzkumy:
- Muži čtou lépe v mapách.
- Ženy jsou možná empatičtější.
- Muži určitě rychleji běhají.
A občas si lidé tyto rozdíly vykreslují takto:
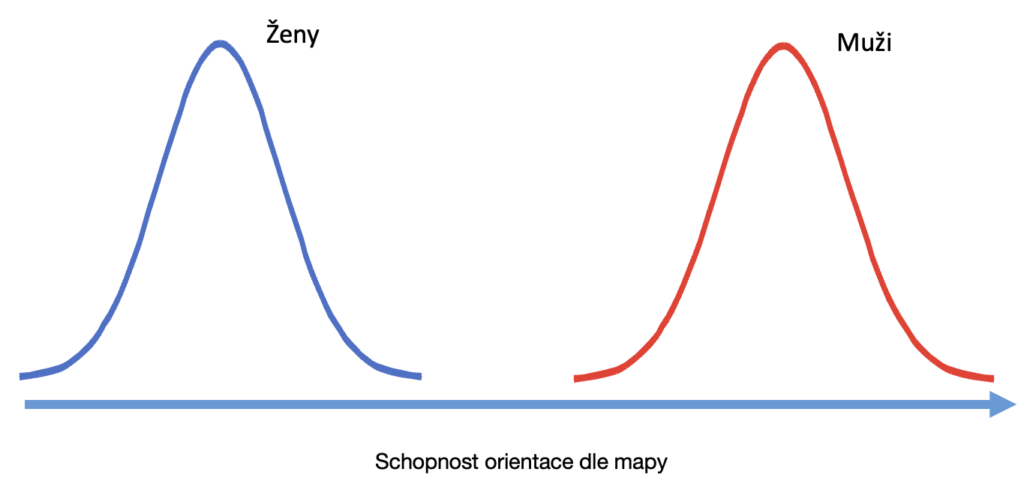
Ve skutečnosti rozdíly vypadají spíše takto:
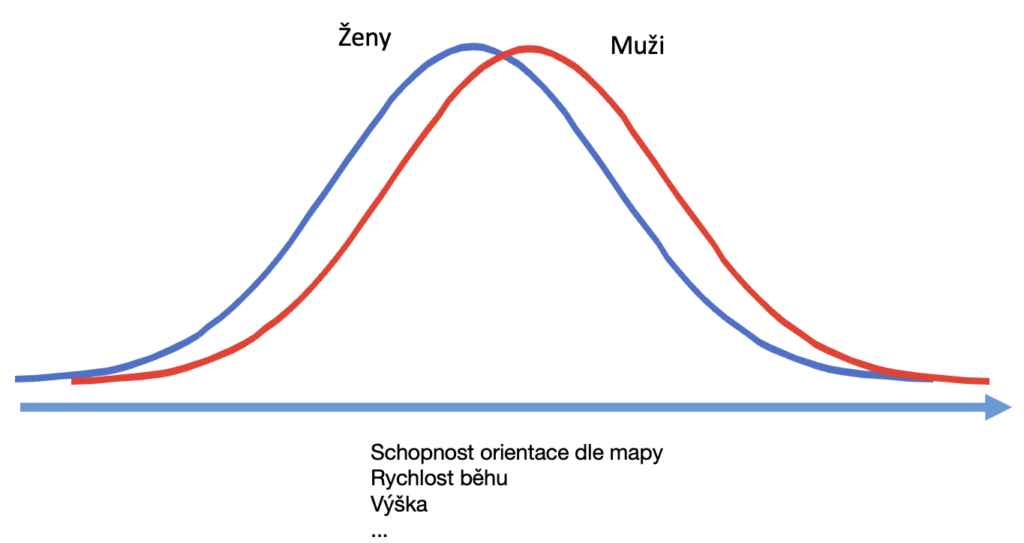
Ve skutečnosti to není tak, že všichni muži čtou v mapách lépe než ženy.
V realitě se jen mírně liší průměry velkých vzorků mužů a velkých vzorků žen.
Stejné to je například v rychlosti běhu. Ano, muži v průměru běhají rychleji než ženy.
Ale jako muž bych já osobně na jakémkoli běžeckém závodu mezi ženami těžce pohořel. Stejně jako velká část jiných mužů.
Takže když uvidíte nějakého muže s mapou v ruce, nelze říct, že zrovna tento muž čte lépe v mapách než nějaká jiná náhodná žena. Dokonce ani že je lepší než průměr žen.
Nepřesná interpretace těchto rozdílů může tedy vést úplně ke zbytečným předsudkům.
Ano, biologické rozdíly mezi muži a ženami existují, ale pouze na statistické a průměrné úrovni.
Příroda nás nevybavila statistickým myšlením. V pralese to nebylo potřeba. Musíme se učit.
Náš mozek je skvěle vybaven pro přežití v pralese.
Tam jsme ale statistiku nepotřebovali.
Ani sedlák se svým rozumem statistiku víceméně nepotřeboval.
A náš mozek tak, jak je zadrátován, neumí moc pracovat se statistickým myšlením.
Musíme se to proto pracně učit a využívat naši šedou kůru mozkovou k tomu, abychom dokázali statisticky přemýšlet.
A stojí to za to. Lepší pochopení statistiky nám pomáhá lépe myslet, lépe se rozhodovat, zbavit se předsudků. Pomáhá nám vidět svět lépe a pravdivěji. A díky tomu i lépe žít.
🙋 Jsem inovátor na volné noze
- Pomáhám firmám s inovačními projekty.
- Učím lidi ve firmách AI a inovační dovednosti.
- Školím jednoduchým jazykem, zábavně a trpělivě.
- Tvořím videa, točím podcast a píšu blog.
Líbilo? Odebírejte můj newsletter 👇
Jestli se vám články líbí, rád vám každý čtvrtek pošlu přehled těch nových za předchozí týden:
Príjemné prekvapivý výklad
S pozdravom Viktória Schmerova.